Django Styleguide - 服务层和选择器(Services & Selectors)
📖 本章概览
本章详细介绍了 Django 中的服务层(Services)和选择器(Selectors)模式:
服务层的设计原则和实现
基于函数 vs 基于类的服务
选择器模式用于数据查询
服务和选择器的测试策略
核心原则:业务逻辑应该集中在服务层,数据查询应该通过选择器。
🎯 核心哲学:读写分离(CQS)
在 Django Styleguide 的架构体系中,我们将业务逻辑层进一步细分为 Services(服务) 和 Selectors(选择器)。这种分类的核心原因在于遵循 命令查询职责分离(CQS/CQRS) 原则。
为什么需要这种分类?
副作用管理(Side Effects):
Services(写) 允许有副作用(发邮件、调 API、修改数据库)。
Selectors(读) 必须是“纯净”的,除了返回数据不应做任何状态改变。明确这一界限能极大地提高代码的可预测性。
职责单一化:
避免在复杂的查询逻辑中夹杂数据修改,从而减少由于副作用导致的难以调试的 Bug。
Services 集中处理“如何改变世界”,Selectors 集中处理“如何观察世界”。
维护与协作效率:
当产品逻辑变更(比如改变注册流程)时,开发者只需查阅
services.py。当页面展示变更(比如需要统计新字段)时,开发者只需查阅
selectors.py。
| 特性 | 服务层 (Services) | 选择器 (Selectors) |
| 主要动作 | 推送 (Push) - 写入数据 | 拉取 (Pull) - 读取数据 |
| 数据库 | Create, Update, Delete | Read, Query, Filter |
| 典型任务 | 扣款、发邮件、创建订单 | 统计报表、搜索过滤、列表展示 |
| 事务性 | 必须保证原子性 (Atomic) | 通常只读,无需事务 |
💡 与 FastAPI / CRUD 模式的对比
如果你有 FastAPI 或 SQLAlchemy 的开发背景,你可能会奇怪:“为什么这里没有 crud.py 文件?”
在 FastAPI 常规则架构中,由于 ORM(如 SQLAlchemy)相对底层,开发者通常会写一个 crud.py 来封装 Session 操作和基础的增删改查。但在本风格指南中,我们不推荐这样做:
Manager 已经是 CRUD 层:Django 的
objects(Manager) 已经是一个非常强大的仓储(Repository)模式实现。像User.objects.create()这种代码已经足够简洁且具备高度可读性,再封装一层纯粹的crud_create_user属于过度封装。职责吸收:
写操作 被吸收进了 Services:我们不关心纯粹的“数据库写入”,我们关心的是带有业务意义的“用户注册”或“订单支付”。
读操作 被吸收进了 Selectors:我们不仅仅是在“获取数据”,而是在“获取符合某种业务场景的数据视图”(如:带统计信息的课程列表)。
结论:在 Django Styleguide 中,我们通过 Service 和 Selector 赋予了 CRUD 行为更明确的“业务语义”,而不是把它们关进一个名为 crud.py 的“数据访问监狱”。
服务层概述
服务层是业务逻辑的所在地。
服务层使用软件的特定领域语言,可以访问数据库和其他资源,并可以与系统的其他部分交互。
🔖 核心概念:服务层(Service Layer)
服务层是一个架构模式,用于:
封装业务逻辑
协调多个模型和外部系统
提供清晰的 API 接口
使代码可测试和可维护
这是一个非常简单的图表,展示了服务层在我们 Django 应用中的位置:
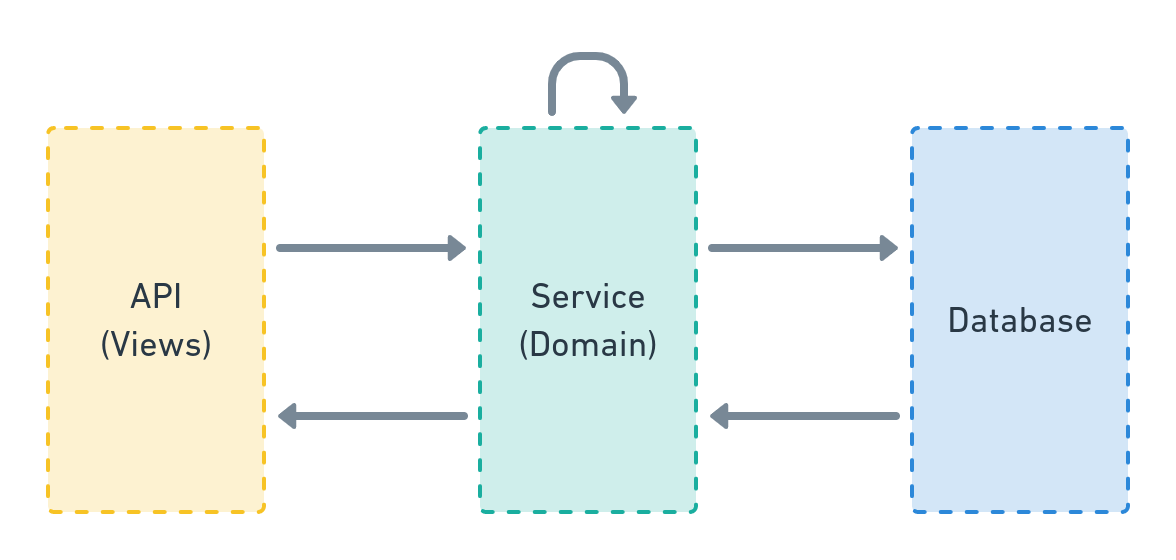
💡 架构层次可视化
查看Mermaid源码
Mermaidgraph LR API[视图 / API 层] -->|1. 调用| SVC(服务层 Service Layer) SVC -->|2. 处理业务逻辑| SVC SVC -->|3. 操作 / 访问| DB[(数据层 Models)] %% 样式美化:显式黑色字体 color:#000 style SVC fill:#f5f7ff,stroke:#5c7cfa,stroke-width:2px,color:#000 style API fill:#fff,stroke:#333,color:#000 style DB fill:#fff,stroke:#333,color:#000
服务可以是:
一个简单的函数。
一个类。
整个模块。
任何对你的具体情况有意义的东西。
💡 选择标准
简单场景:使用函数
需要共享状态/配置:使用类
复杂领域:使用模块
多步骤流程:使用类(带状态)
在大多数情况下,服务可以是一个简单的函数,它:
位于
<your_app>/services.py模块中。接受关键字参数,除非它不需要参数或只需要一个参数。
有类型注解(即使你目前没有使用
mypy)。与数据库、其他资源和系统的其他部分交互。
执行业务逻辑 - 从简单的模型创建到复杂的跨领域关注点,再到调用外部服务和任务。
⚠️ 关键字参数的重要性
python# ❌ 错误:使用位置参数(难以维护) def user_create(email, name, password): pass # ✅ 正确:使用关键字参数(清晰明了) def user_create(*, email: str, name: str, password: str) -> User: pass # 调用时必须指定参数名 user_create(email="test@example.com", name="Test", password="secret")好处:
代码更清晰
避免参数顺序错误
易于重构和扩展
示例 - 基于函数的服务
创建用户的服务示例:
def user_create(
*,
email: str,
name: str
) -> User:
user = User(email=email)
user.full_clean()
user.save()
profile_create(user=user, name=name)
confirmation_email_send(user=user)
return user
📝 代码详解
这个服务展示了几个关键概念:
类型注解:
*,:强制使用关键字参数
email: str:参数类型提示
-> User:返回类型提示职责清晰:
创建用户对象
验证数据(
full_clean())保存到数据库
调用其他服务(创建资料、发送邮件)
组合性:
调用其他服务(
profile_create,confirmation_email_send)每个服务负责一个明确的任务
如你所见,这个服务调用了 2 个其他服务 - profile_create 和 confirmation_email_send。
在这个例子中,与用户创建相关的所有内容都在一个地方,可以被追踪。
💡 服务的可追溯性
这是服务层的巨大优势:
python# 只需查看这一个函数,就能了解用户创建的完整流程 def user_create(...): # 1. 创建用户 # 2. 创建资料 # 3. 发送邮件 # 所有步骤都清晰可见!对比如果逻辑分散在多处:
Serializer 中创建用户
Signal 中创建资料
View 中发送邮件
很难理解完整流程!
✅ 更多实际示例
pythonfrom django.db import transaction from typing import List @transaction.atomic def order_create( *, user: User, items: List[dict], shipping_address: str ) -> Order: """创建订单的完整业务逻辑""" # 验证库存 inventory_check(items=items) # 计算价格 total = calculate_order_total(items=items) # 创建订单 order = Order( user=user, total=total, shipping_address=shipping_address ) order.full_clean() order.save() # 添加订单项 for item_data in items: order_item_create(order=order, **item_data) # 减少库存 inventory_decrease(items=items) # 发送确认邮件 order_confirmation_email_send(order=order) # 触发支付流程 payment_process_async.delay(order.id) return order def article_publish(*, article: Article, published_by: User) -> Article: """发布文章""" if article.status == Article.Status.PUBLISHED: raise ValidationError("文章已经发布") if not published_by.has_perm('articles.publish_article'): raise PermissionDenied("没有发布权限") article.status = Article.Status.PUBLISHED article.published_at = timezone.now() article.published_by = published_by article.save() # 通知订阅者 notify_subscribers.delay(article.id) return article
示例 - 基于类的服务
此外,我们还可以有"基于类的"服务,这是一种花哨的说法 - 将逻辑包装在一个类中。
🔖 何时使用基于类的服务
适合以下场景:
需要共享配置或状态
有多个相关操作(如 create 和 update)
需要复用私有辅助方法
实现多步骤流程
这是一个直接从 Django Styleguide Example 中提取的与文件上传相关的示例:
# https://github.com/HackSoftware/Django-Styleguide-Example/blob/master/styleguide_example/files/services.py
class FileStandardUploadService:
"""
这也是一个服务类的示例,
它在一个命名空间下封装了 2 种不同的行为(create 和 update)。
也就是说,我们在这里使用类是为了:
1. 命名空间
2. 能够重用 `_infer_file_name_and_type`(它也可以是一个工具函数)
"""
def __init__(self, user: BaseUser, file_obj):
self.user = user
self.file_obj = file_obj
def _infer_file_name_and_type(self, file_name: str = "", file_type: str = "") -> Tuple[str, str]:
file_name = file_name or self.file_obj.name
if not file_type:
guessed_file_type, encoding = mimetypes.guess_type(file_name)
file_type = guessed_file_type or ""
return file_name, file_type
@transaction.atomic
def create(self, file_name: str = "", file_type: str = "") -> File:
_validate_file_size(self.file_obj)
file_name, file_type = self._infer_file_name_and_type(file_name, file_type)
obj = File(
file=self.file_obj,
original_file_name=file_name,
file_name=file_generate_name(file_name),
file_type=file_type,
uploaded_by=self.user,
upload_finished_at=timezone.now()
)
obj.full_clean()
obj.save()
return obj
@transaction.atomic
def update(self, file: File, file_name: str = "", file_type: str = "") -> File:
_validate_file_size(self.file_obj)
file_name, file_type = self._infer_file_name_and_type(file_name, file_type)
file.file = self.file_obj
file.original_file_name = file_name
file.file_name = file_generate_name(file_name)
file.file_type = file_type
file.uploaded_by = self.user
file.upload_finished_at = timezone.now()
file.full_clean()
file.save()
return file
📝 代码详解
这个类展示了基于类的服务的优势:
命名空间:
FileStandardUploadService提供清晰的命名空间相关操作(create/update)组织在一起
状态共享:
self.user和self.file_obj在所有方法中可用避免重复传递参数
代码重用:
_infer_file_name_and_type被两个方法使用私有方法(
_前缀)表示内部使用事务管理:
@transaction.atomic确保数据一致性如果出错,所有更改都会回滚
如注释中所述,我们使用这种方法有 2 个主要原因:
命名空间。 我们为 create 和 update 提供了一个单一的命名空间。
重用
_infer_file_name_and_type逻辑。
这是如何使用这个服务的:
# https://github.com/HackSoftware/Django-Styleguide-Example/blob/master/styleguide_example/files/apis.py
class FileDirectUploadApi(ApiAuthMixin, APIView):
def post(self, request):
service = FileStandardUploadService(
user=request.user,
file_obj=request.FILES["file"]
)
file = service.create()
return Response(data={"id": file.id}, status=status.HTTP_201_CREATED)
💡 API 中使用服务
注意 API 的职责:
获取请求数据
实例化服务
调用服务方法
返回响应
所有业务逻辑都在服务中!
以及:
@admin.register(File)
class FileAdmin(admin.ModelAdmin):
# ... 其他代码在这里 ...
# https://github.com/HackSoftware/Django-Styleguide-Example/blob/master/styleguide_example/files/admin.py
def save_model(self, request, obj, form, change):
try:
cleaned_data = form.cleaned_data
service = FileStandardUploadService(
file_obj=cleaned_data["file"],
user=cleaned_data["uploaded_by"]
)
if change:
service.update(file=obj)
else:
service.create()
except ValidationError as exc:
self.message_user(request, str(exc), messages.ERROR)
💡 在 Django Admin 中使用服务
同样的服务可以在不同的地方使用:
API 接口
Django Admin
管理命令
Celery 任务
这就是分离业务逻辑的价值!
此外,使用基于类的服务对于"流程"很有用 - 需要经过多个步骤的事情。
例如,这个服务代表一个"直接文件上传流程",有一个 start 和 finish(以及其他):
# https://github.com/HackSoftware/Django-Styleguide-Example/blob/master/styleguide_example/files/services.py
class FileDirectUploadService:
"""
这也是一个服务类的示例,
它将一个流程(start 和 finish)+ 一次性操作(upload_local)封装到命名空间中。
也就是说,我们在这里使用类是为了:
1. 命名空间
"""
def __init__(self, user: BaseUser):
self.user = user
@transaction.atomic
def start(self, *, file_name: str, file_type: str) -> Dict[str, Any]:
file = File(
original_file_name=file_name,
file_name=file_generate_name(file_name),
file_type=file_type,
uploaded_by=self.user,
file=None
)
file.full_clean()
file.save()
upload_path = file_generate_upload_path(file, file.file_name)
"""
我们这样做是为了让字段有一个关联的文件。
"""
file.file = file.file.field.attr_class(file, file.file.field, upload_path)
file.save()
presigned_data: Dict[str, Any] = {}
if settings.FILE_UPLOAD_STORAGE == FileUploadStorage.S3:
presigned_data = s3_generate_presigned_post(
file_path=upload_path, file_type=file.file_type
)
else:
presigned_data = {
"url": file_generate_local_upload_url(file_id=str(file.id)),
}
return {"id": file.id, **presigned_data}
@transaction.atomic
def finish(self, *, file: File) -> File:
# 可能需要验证用户权限
file.upload_finished_at = timezone.now()
file.full_clean()
file.save()
return file
📝 多步骤流程服务
这个例子展示了处理复杂流程的服务:
start()方法:
创建文件记录
生成上传 URL(可能是 S3 预签名 URL)
返回客户端需要的信息
finish()方法:
标记上传完成
更新时间戳
验证和保存
流程:
TEXT客户端调用 start() → 获取上传 URL ↓ 客户端上传文件到 URL ↓ 客户端调用 finish() → 完成流程
✅ 更多基于类的服务示例
pythonclass UserRegistrationService: """用户注册流程服务""" def __init__(self, email: str, password: str): self.email = email self.password = password self.user = None def validate(self) -> bool: """步骤 1: 验证""" if User.objects.filter(email=self.email).exists(): raise ValidationError("邮箱已存在") if len(self.password) < 8: raise ValidationError("密码太短") return True @transaction.atomic def create_user(self) -> User: """步骤 2: 创建用户""" self.user = User(email=self.email) self.user.set_password(self.password) self.user.full_clean() self.user.save() return self.user def send_verification(self): """步骤 3: 发送验证邮件""" token = generate_verification_token(self.user) send_verification_email.delay(self.user.id, token) def execute(self) -> User: """执行完整流程""" self.validate() self.create_user() self.send_verification() return self.user # 使用 service = UserRegistrationService( email="user@example.com", password="secret123" ) user = service.execute()
命名规范
命名规范取决于你的品味。在整个项目中保持一致会有回报。
如果我们采用上面的例子,我们的服务名为 user_create。模式是 - <entity>_<action>。
🔖 命名模式:
entity_action格式:
{实体名}_{动作}示例:
user_create
user_update
order_cancel
payment_process
article_publish
这是我们在 HackSoft 项目中的首选。这在一开始看起来很奇怪,但它有几个不错的特点:
命名空间。 很容易识别所有以
user_开头的服务,并且将它们放在users.py模块中是个好主意。可搜索性。 换句话说,如果你想查看特定实体的所有操作,只需搜索
user_。
💡 命名规范的价值
TEXT# 文件结构 services/ ├── users.py # user_create, user_update, user_delete ├── orders.py # order_create, order_cancel, order_refund ├── payments.py # payment_process, payment_refund └── notifications.py # notification_send, notification_mark_read好处:
在 IDE 中输入
user_会自动补全所有用户相关服务使用
grep "user_"可以找到所有用户操作清晰的代码组织
💡 其他命名风格
如果你喜欢其他风格,也可以:
python# 风格 1: 动词在前 def create_user(*, email: str) -> User: pass # 风格 2: 类风格 class UserService: @staticmethod def create(*, email: str) -> User: pass # 风格 3: 完整描述 def create_new_user_account(*, email: str) -> User: pass关键是在项目中保持一致!
模块组织
如果你有一个足够简单的 Django 应用,有一堆服务,它们都可以愉快地存在于 service.py 模块中。
但当事情变得庞大时,你可能想要将 services.py 拆分成一个包含子模块的文件夹,这取决于你在应用中处理的不同子领域。
💡 何时拆分服务模块
保持单文件的情况:
服务数量 < 10 个
所有服务都紧密相关
文件行数 < 500
拆分的情况:
服务数量 > 10 个
有明确的子领域
文件行数 > 500
团队成员经常冲突
例如,假设我们有一个 authentication 应用,在我们的 services 模块中,我们有 1 个处理 jwt 的子模块,以及一个处理 oauth 的子模块。
结构可能如下所示:
services
├── __init__.py
├── jwt.py
└── oauth.py
📝 实际项目结构示例
TEXTusers/ ├── models.py ├── services/ │ ├── __init__.py │ ├── authentication.py # user_login, user_logout, user_refresh_token │ ├── registration.py # user_register, user_verify_email │ ├── profile.py # user_update_profile, user_change_password │ └── permissions.py # user_grant_permission, user_revoke_permission ├── selectors/ │ ├── __init__.py │ └── users.py # user_list, user_get, user_get_by_email └── apis.py
这里有很多变化:
你可以在
services/__init__.py中进行导入导出操作,这样你就可以在其他地方从project.authentication.services导入。你可以创建一个文件夹模块,
jwt/__init__.py,并将代码放在那里。基本上,结构由你决定。如果你觉得是时候重组和重构了 - 那就去做。
💡
__init__.py导入导出模式python# services/__init__.py from .authentication import ( user_login, user_logout, user_refresh_token, ) from .registration import ( user_register, user_verify_email, ) from .profile import ( user_update_profile, user_change_password, ) __all__ = [ 'user_login', 'user_logout', 'user_refresh_token', 'user_register', 'user_verify_email', 'user_update_profile', 'user_change_password', ]使用时:
python# 可以直接从 services 导入 from project.users.services import user_login, user_register # 而不是 from project.users.services.authentication import user_login from project.users.services.registration import user_register
✅ 大型项目的最佳实践
TEXT# 按功能领域组织 ecommerce/ ├── orders/ │ ├── services/ │ │ ├── creation.py # 订单创建相关 │ │ ├── payment.py # 支付处理相关 │ │ ├── shipping.py # 发货相关 │ │ └── cancellation.py # 取消/退款相关 │ └── selectors/ │ ├── orders.py │ └── statistics.py ├── inventory/ │ ├── services/ │ │ ├── stock.py # 库存管理 │ │ └── suppliers.py # 供应商管理 │ └── selectors/ │ └── inventory.py └── catalog/ ├── services/ │ ├── products.py # 产品管理 │ └── categories.py # 分类管理 └── selectors/ └── products.py
选择器(Selectors)
在我们的大多数项目中,我们区分"向数据库推送数据"和"从数据库拉取数据":
Services 负责推送(写入)。
Selectors 负责拉取(读取)。
Selectors 可以被视为服务的"子层",专门用于获取数据。
🔖 选择器模式(Selector Pattern)
Selectors 是专门用于数据查询的函数:
只读操作
返回查询集或对象
可以包含复杂的过滤和连接逻辑
封装数据访问细节
💡 Services vs Selectors
特性 Services Selectors 主要操作 Create, Update, Delete Read, Query 数据库操作 修改数据 只读数据 事务 通常需要 通常不需要 返回值 对象实例 查询集或对象 副作用 有(发邮件、调 API) 无
💡 如果这个想法与你的想法不一致
如果这个想法与你的想法不一致,你可以只为两"种"操作都使用 services。
这完全取决于你的偏好和项目需求!
选择器遵循与服务相同的规则。
例如,在 <your_app>/selectors.py 模块中,我们可以有以下内容:
def user_list(*, fetched_by: User) -> Iterable[User]:
user_ids = user_get_visible_for(user=fetched_by)
query = Q(id__in=user_ids)
return User.objects.filter(query)
📝 代码详解
fetched_by参数用于权限控制(用户只能看到特定用户)调用另一个 selector(
user_get_visible_for)获取可见用户 ID使用
Q对象构建查询返回 QuerySet(不是列表)
如你所见,user_get_visible_for 是另一个选择器。
你可以返回查询集、列表或任何对你的具体情况有意义的东西。
⚠️ 返回 QuerySet vs List
python# ✅ 推荐:返回 QuerySet(可以继续链式调用) def user_list(*, is_active: bool = True) -> QuerySet[User]: return User.objects.filter(is_active=is_active) # 使用时可以继续过滤 users = user_list().filter(email__endswith='@example.com') # ⚠️ 返回 List(不能继续查询) def user_list(*, is_active: bool = True) -> List[User]: return list(User.objects.filter(is_active=is_active)) # 使用时已经是列表,不能继续数据库查询 users = user_list() # 已经执行查询了
✅ 更多 Selector 示例
pythonfrom django.db.models import QuerySet, Q, Prefetch from typing import Optional def user_get_by_email(*, email: str) -> Optional[User]: """通过邮箱获取用户""" try: return User.objects.get(email=email) except User.DoesNotExist: return None def user_list_with_profiles( *, filters: dict = None ) -> QuerySet[User]: """获取用户列表,优化关联查询""" filters = filters or {} return User.objects.select_related( 'profile' ).filter(**filters) def order_list_for_user( *, user: User, status: Optional[str] = None ) -> QuerySet[Order]: """获取用户的订单列表""" queryset = Order.objects.filter(user=user) if status: queryset = queryset.filter(status=status) return queryset.select_related( 'user' ).prefetch_related( 'items__product' ).order_by('-created_at') def article_list_published( *, category: Optional[str] = None, tag: Optional[str] = None ) -> QuerySet[Article]: """获取已发布的文章列表""" queryset = Article.objects.filter( status=Article.Status.PUBLISHED, published_at__lte=timezone.now() ) if category: queryset = queryset.filter(category=category) if tag: queryset = queryset.filter(tags__name=tag) return queryset.select_related( 'author', 'category' ).prefetch_related( 'tags' ).distinct() def product_search( *, query: str, category: Optional[int] = None, min_price: Optional[Decimal] = None, max_price: Optional[Decimal] = None ) -> QuerySet[Product]: """产品搜索""" queryset = Product.objects.filter(is_active=True) # 全文搜索 if query: queryset = queryset.filter( Q(name__icontains=query) | Q(description__icontains=query) ) # 分类过滤 if category: queryset = queryset.filter(category_id=category) # 价格范围 if min_price: queryset = queryset.filter(price__gte=min_price) if max_price: queryset = queryset.filter(price__lte=max_price) return queryset.select_related('category')
💡 Selector 的高级技巧
python# 1. 使用 django-filter import django_filters class UserFilter(django_filters.FilterSet): class Meta: model = User fields = { 'email': ['exact', 'icontains'], 'is_active': ['exact'], 'created_at': ['gte', 'lte'], } def user_list(*, filters: dict = None) -> QuerySet[User]: filters = filters or {} queryset = User.objects.all() return UserFilter(filters, queryset).qs # 2. 预取优化 def order_list_with_items() -> QuerySet[Order]: return Order.objects.prefetch_related( Prefetch( 'items', queryset=OrderItem.objects.select_related('product') ) ) # 3. 聚合查询 from django.db.models import Count, Sum, Avg def user_list_with_stats() -> QuerySet[User]: return User.objects.annotate( order_count=Count('orders'), total_spent=Sum('orders__total'), avg_order_value=Avg('orders__total') )
测试
由于服务层包含我们的业务逻辑,它们是测试的理想候选对象。
💡 架构反思:为什么要测 Service 而不只是 API?
很多开发者会疑惑:如果 API 测试已经覆盖了路径,还需要单独测 Service 吗?
“大脑”与“皮肤”的解耦:API 只是系统的“皮肤”,而 Service 是“大脑”。你的逻辑以后可能会被 Celery 任务、管理脚本或集成服务调用。单独测试 Service 能确保“大脑”在任何环境下都是清醒的,不需要依赖 HTTP 环境。
拒绝“重构恐惧症”:随着项目增长,你最怕的是改动一处代码导致支付崩掉。Service 测试是你未来的“商业保险”。
报错精度:Service 测试失败会直接指明哪个具体业务分支崩了,而不是泛泛的
400 Bad Request。
🚀 实战建议:抓大放小
我们不鼓励为了追求 100% 覆盖率 而浪费生命(那是无意义的数据游戏)。我们推荐 “基于价值的测试”:
| 优先级 | 场景 | 测试策略 |
| P0:核心业务 | 扣款、发货、权限变更、状态流转 | 必须详尽测试,这是系统的生命线。 |
| P1:复杂计算 | 折扣矩阵、复杂的统计逻辑、算法输出 | 必须详尽测试,人脑极易在这些地方遗漏边界情况。 |
| P2:简单 CRUD | 创建一个空的 User、修改一个简单的字段 | 可选择不测,这种逻辑在 API 测试中顺便跑一下即可。 |
如果你决定用测试覆盖服务层,我们有几条要遵循的一般经验法则:
测试应该详尽地覆盖业务逻辑。
测试应该访问数据库 - 从中创建和读取。
测试应该模拟异步任务调用以及所有超出项目范围的内容。
💡 服务测试的三个原则
详尽覆盖:测试所有业务场景和边界情况
真实数据库:使用测试数据库,不要 mock ORM
模拟外部:mock 外部 API、异步任务、邮件发送等
当为给定测试创建所需状态时,可以使用以下组合:
Fakes(我们推荐使用
faker)其他服务,用于创建所需对象。
特殊的测试工具和辅助方法。
Factories(我们推荐使用
factory_boy)如果项目中尚未引入工厂,则使用普通的
Model.objects.create()调用。通常,任何更适合你的方法。
🔖 测试数据准备工具
Faker:生成假数据(姓名、邮箱、地址等)
Factory Boy:创建模型实例的工厂
直接创建:使用
Model.objects.create()辅助函数:自定义的
given_a_user()等
让我们看看我们示例中的服务:
from django.contrib.auth.models import User
from django.core.exceptions import ValidationError
from django.db import transaction
from project.payments.selectors import items_get_for_user
from project.payments.models import Item, Payment
from project.payments.tasks import payment_charge
@transaction.atomic
def item_buy(
*,
item: Item,
user: User,
) -> Payment:
if item in items_get_for_user(user=user):
raise ValidationError(f'Item {item} already in {user} items.')
payment = Payment(
item=item,
user=user,
successful=False
)
payment.full_clean()
payment.save()
# 在事务提交后运行任务,
# 保证对象已经创建。
transaction.on_commit(
lambda: payment_charge.delay(payment_id=payment.id)
)
return payment
📝 服务代码分析
这个服务展示了几个要测试的关键点:
验证逻辑:检查用户是否已拥有该物品
对象创建:创建支付记录
异步任务:延迟执行支付扣款
事务管理:确保任务在事务提交后执行
服务:
调用一个选择器进行验证。
创建一个对象。
延迟一个任务。
这些是我们的测试:
from unittest.mock import patch, Mock
from django.test import TestCase
from django.contrib.auth.models import User
from django.core.exceptions import ValidationError
from django_styleguide.payments.services import item_buy
from django_styleguide.payments.models import Payment, Item
class ItemBuyTests(TestCase):
@patch('project.payments.services.items_get_for_user')
def test_buying_item_that_is_already_bought_fails(
self, items_get_for_user_mock: Mock
):
"""
由于我们已经为 `items_get_for_user` 编写了测试,
我们可以在这里安全地模拟它并给它一个适当的返回值。
"""
user = User(username='Test User')
item = Item(
name='Test Item',
description='Test Item description',
price=10.15
)
items_get_for_user_mock.return_value = [item]
with self.assertRaises(ValidationError):
item_buy(user=user, item=item)
@patch('project.payments.services.payment_charge.delay')
def test_buying_item_creates_a_payment_and_calls_charge_task(
self,
payment_charge_mock: Mock
):
# 如何准备测试是另一个讨论的话题
user = given_a_user(username="Test user")
item = given_a_item(
name='Test Item',
description='Test Item description',
price=10.15
)
self.assertEqual(0, Payment.objects.count())
payment = item_buy(user=user, item=item)
self.assertEqual(1, Payment.objects.count())
self.assertEqual(payment, Payment.objects.first())
self.assertFalse(payment.successful)
payment_charge_mock.assert_called_once()
📝 测试代码详解
测试 1:验证业务规则
Mock selector 返回值
不访问数据库(selector 已单独测试)
验证异常被正确抛出
测试 2:验证完整流程
使用辅助函数创建测试数据
检查数据库状态变化
Mock 异步任务
验证任务被调用
💡 测试的关键点
Mock 选择器:
python@patch('project.payments.services.items_get_for_user') def test_something(self, mock): mock.return_value = [item] # 控制返回值Mock 任务:
python@patch('project.payments.services.payment_charge.delay') def test_something(self, mock): # 测试服务逻辑 mock.assert_called_once() # 验证任务被调用验证数据库状态:
pythonself.assertEqual(0, Payment.objects.count()) # 执行操作 self.assertEqual(1, Payment.objects.count())
✅ 更完整的测试示例
pythonfrom decimal import Decimal from unittest.mock import patch, Mock from django.test import TestCase from django.core.exceptions import ValidationError class OrderCreateServiceTests(TestCase): def setUp(self): """测试前准备""" self.user = User.objects.create( email="test@example.com", username="testuser" ) self.product = Product.objects.create( name="Test Product", price=Decimal("100.00"), stock=10 ) def test_create_order_with_valid_data(self): """测试正常创建订单""" items = [ {'product_id': self.product.id, 'quantity': 2} ] order = order_create( user=self.user, items=items, shipping_address="Test Address" ) self.assertIsNotNone(order.id) self.assertEqual(order.user, self.user) self.assertEqual(order.items.count(), 1) self.assertEqual(order.total, Decimal("200.00")) def test_create_order_with_insufficient_stock_fails(self): """测试库存不足时失败""" items = [ {'product_id': self.product.id, 'quantity': 20} ] with self.assertRaises(ValidationError) as ctx: order_create( user=self.user, items=items, shipping_address="Test Address" ) self.assertIn('库存不足', str(ctx.exception)) @patch('project.orders.services.order_confirmation_email_send.delay') def test_create_order_sends_confirmation_email(self, mock_email): """测试创建订单后发送确认邮件""" items = [ {'product_id': self.product.id, 'quantity': 1} ] order = order_create( user=self.user, items=items, shipping_address="Test Address" ) mock_email.assert_called_once_with(order.id) @patch('project.orders.services.payment_process_async.delay') def test_create_order_triggers_payment(self, mock_payment): """测试创建订单后触发支付""" items = [ {'product_id': self.product.id, 'quantity': 1} ] order = order_create( user=self.user, items=items, shipping_address="Test Address" ) mock_payment.assert_called_once_with(order.id) def test_create_order_decreases_stock(self): """测试创建订单后减少库存""" original_stock = self.product.stock items = [ {'product_id': self.product.id, 'quantity': 2} ] order_create( user=self.user, items=items, shipping_address="Test Address" ) self.product.refresh_from_db() self.assertEqual( self.product.stock, original_stock - 2 )
💡 测试最佳实践
一个测试一个场景
python# ✅ 好 def test_create_user_with_valid_email(self): pass def test_create_user_with_invalid_email_fails(self): pass # ❌ 不好 def test_create_user(self): # 测试多个场景...使用描述性的测试名称
python# ✅ 好 def test_buying_item_that_is_already_bought_fails(self): # ❌ 不好 def test_item_buy(self):准备-执行-断言(AAA)模式
pythondef test_something(self): # Arrange(准备) user = given_a_user() item = given_an_item() # Act(执行) result = item_buy(user=user, item=item) # Assert(断言) self.assertIsNotNone(result.id)Mock 外部依赖
python# Mock 异步任务 @patch('app.services.send_email.delay') # Mock 外部 API @patch('app.services.payment_gateway.charge') # Mock 选择器(如果已单独测试) @patch('app.services.user_get_by_email')
📝 本章总结
本章介绍了服务层和选择器的最佳实践:
核心要点
服务层(Services)
业务逻辑的集中地
可以是函数或类
负责数据写入和复杂操作
协调多个模型和外部系统
选择器(Selectors)
专门用于数据查询
只读操作
返回查询集或对象
封装数据访问逻辑
命名规范
推荐:
entity_action模式例如:
user_create,order_cancel提供良好的命名空间和可搜索性
模块组织
小项目:单个
services.py文件大项目:按领域拆分成多个模块
使用
__init__.py导出公共 API
测试策略
详尽覆盖业务逻辑
真实访问数据库
Mock 外部依赖(任务、API)
使用 AAA 模式
决策指南
何时使用基于函数的服务?
✅ 简单的单一操作
✅ 不需要共享状态
✅ 大多数情况
何时使用基于类的服务?
✅ 需要共享配置或状态
✅ 多个相关操作(create/update)
✅ 多步骤流程
✅ 需要复用辅助方法
Services vs Selectors?
Services:Create, Update, Delete + 复杂业务逻辑
Selectors:Read, Query + 数据获取
记住
服务层是业务逻辑的唯一真实来源。API、Admin、命令行都应该调用服务,而不是包含业务逻辑。
下一章预告: 在下一章中,我们将详细介绍 API 和序列化器,了解如何设计清晰的 API 接口。
相关章节: